 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYair Even-Zohar
A Sequential Model for Multi-Class Classification
Jun 20, 2001
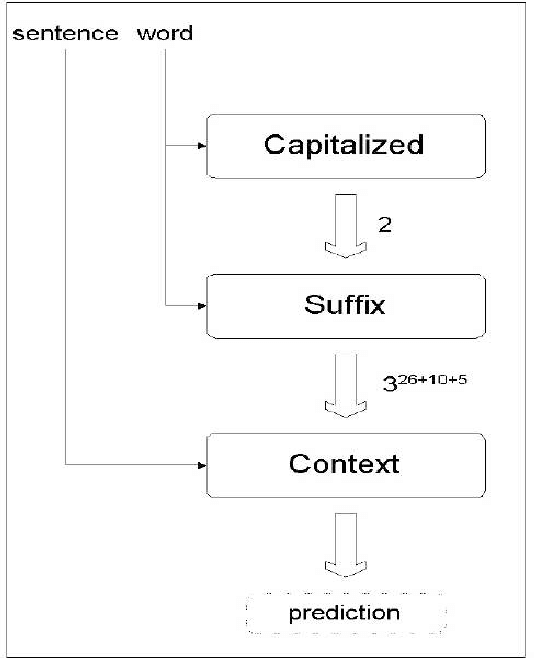
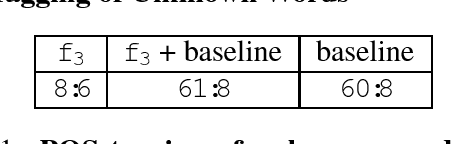
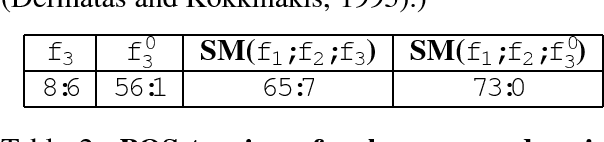

Many classification problems require decisions among a large number of competing classes. These tasks, however, are not handled well by general purpose learning methods and are usually addressed in an ad-hoc fashion. We suggest a general approach -- a sequential learning model that utilizes classifiers to sequentially restrict the number of competing classes while maintaining, with high probability, the presence of the true outcome in the candidates set. Some theoretical and computational properties of the model are discussed and we argue that these are important in NLP-like domains. The advantages of the model are illustrated in an experiment in part-of-speech tagging.
A Classification Approach to Word Prediction
Sep 28, 2000
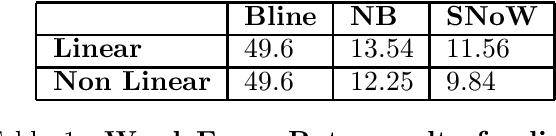

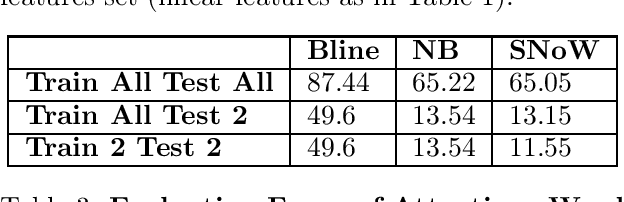
The eventual goal of a language model is to accurately predict the value of a missing word given its context. We present an approach to word prediction that is based on learning a representation for each word as a function of words and linguistics predicates in its context. This approach raises a few new questions that we address. First, in order to learn good word representations it is necessary to use an expressive representation of the context. We present a way that uses external knowledge to generate expressive context representations, along with a learning method capable of handling the large number of features generated this way that can, potentially, contribute to each prediction. Second, since the number of words ``competing'' for each prediction is large, there is a need to ``focus the attention'' on a smaller subset of these. We exhibit the contribution of a ``focus of attention'' mechanism to the performance of the word predictor. Finally, we describe a large scale experimental study in which the approach presented is shown to yield significant improvements in word prediction tasks.
* 8 pages